 SDN – Software Development Network SDN – Software Development Network – De SDN verenigt software ontwikkelaars, architecten, ICT managers, studenten, new media developers en haar businesspartners met algemene interesse in alle aspecten van Microsoft en .NET.
SDN – Software Development Network SDN – Software Development Network – De SDN verenigt software ontwikkelaars, architecten, ICT managers, studenten, new media developers en haar businesspartners met algemene interesse in alle aspecten van Microsoft en .NET.
Je gooit een app in productie en dat is het dan… Toch? Vroeger was het vaak dat je eigenlijk geen zicht had. Je applicatie ging als het ware een roadtrip maken waar je niet direct bij kon zijn. Als er dan iets mis was dan hoorde je dat vaak achteraf en indirect. Via gebruikers bijvoorbeeld. Vervolgens kon je de logs achterhalen door ze op te gaan vragen bij een beheerder om vervolgens te gaan ploeteren door een redelijk grote hoeveelheid tekst, maar haalde je er dan ook echt uit wat je nodig had?
Auteur: Vincent Hendriks
Als er 1 ding is wat tegenwoordig in vrijwel iedere applicatie aanwezig is dan is het wel logging. Als er iets misgaat is dit ook vaak 1 van de eerste dingen waar we naar kijken.
Waarom loggen we eigenlijk?
Voordat we verder gaan, waarom loggen we eigenlijk?
Hoe ik er in ieder geval tegenaan kijk is dat we vaak ons best doen om een applicatie zo robuust mogelijk te ontwikkelen, maar er toch altijd iets mis zal gaan. Als dit gebeurt willen we eigenlijk altijd de logs erbij kunnen pakken om te gaan kijken wat er nu precies gebeurt, toch?
Vragen die je jezelf zult stellen zijn o.a.:
- Wat was nou precies de foutmelding?
- Wat gebeurde er voordat dit probleem optrad?
- Hadden meerdere gebruikers hier last van?
In dit geval gebruiken we de logs als een diagnostische tool.
Een andere reden om logging toe te passen is bijvoorbeeld t.b.v. monitoring/analytics:
- Hoeveel requests per seconde zijn er nu?
- Wat is de gemiddelde responsetijd?
- Hoeveel orders per minuut zijn er nu?
Vervolgens kunnen we deze logging weer gebruiken om alerts af te laten gaan als er bijvoorbeeld enkele van die bovenstaande waardes boven/ onder een bepaalde grens komen.
Wat de reden ook is, je zult vast ook wel weten hoe lastig dat soms kan zijn als je dit allemaal uit pure tekst zou moeten halen. Dit is waar gestructureerde logging van pas komt.
Gestructureerde logging
Gestructureerde logging (soms ook semantische logging genoemd) doet eigenlijk precies wat de naam al zegt. Het zorgt ervoor dat je niet alleen een platte tekst logt, maar gestructureerde data.
In dit artikel maak ik qua voorbeelden gebruik van Serilog i.c.m. Microsoft’s abstractie laag t.b.v. logging, maar dit kan natuurlijk ook op andere manieren ofwel talen/ontwikkelomgevingen.
Laten we eerst eens kijken naar een simpel voorbeeld, hoe het niet moet, waarbij er een foutmelding wordt gelogd:
_logger.LogError(exception, $"An error occurred trying to save order: {order.Id}")
Wat voor data zien wij hier als we dit naar een eenvoudig log bestand zouden wegschrijven?
Typisch zal dit dan het tijdstip, de log level, de foutmelding met stacktrace zijn en een tekst regel met daarin een order id verwerkt. Als we in hetzelfde log bestand zouden gaan zoeken naar een specifieke order id dan is er een grote kans dat we dit gaan vinden, maar wat nou als we iets anders hadden dan het order id? Bijvoorbeeld een klant id of nog beter een error id die we als response melding hebben gegeven.
We kunnen natuurlijk deze ontbrekende informatie toevoegen aan deze log actie, maar daar hebben we op dat moment niks aan. We weten nou eenmaal niet altijd wat we precies nodig gaan hebben totdat we ergens tegen aan lopen en het blijkt dat we iets missen.
Overigens verdwijnt dit probleem natuurlijk nooit helemaal, maar we kunnen het wel zo veel mogelijk proberen te voorkomen. Los daarvan denk ik ook dat niemand heel erg vrolijk wordt op het moment dat we ellenlange log acties in onze code gaan schrijven alleen maar omdat we allerlei extra data willen gaan loggen.
Een ander probleem wat we hier zien is dat als we de data willen verwerken/doorzoeken dat we de tekst moeten gaan parsen.
Om deze 2 punten te gaan verbeteren gaan we als eerste deze log actie een klein beetje herschrijven naar:
_logger.LogError(exception, "An error occurred trying to save order: {orderId}", order.Id)
Er zijn nu een aantal dingen die veranderd zijn:
- Op het moment dat de configuratie zegt dat we alleen critical logging willen wegschrijven dan zal er geen string concatenatie plaats vinden, omdat deze log actie een lagere level heeft.
- Een log provider kan de eventuele parameters apart verwerken. In dit geval zou de orderId dus, naast de tekst weergave van de logregel, apart opgeslagen kunnen worden.Wanneer we bijvoorbeeld Serilog gebruiken dan geeft Serilog alle parameters door naar de onderliggende “log sinks”/ log providers. Een “sink” bepaald hoe en waarheen een log item weggeschreven gaat worden. Je kunt hier denken aan de Console, Files, SQL Server, etc.
Dit lost, afhankelijk van de gekozen sink, in ieder geval het probleem op van het tekst parsen. We kunnen alleen nog een stapje verder:
_logger.LogError(exception, "An error occurred trying to save order: {@order}", order)
Er is eigenlijk, qua code, maar 1 klein verschil: In plaats van een order id hebben we het gehele order object meegegeven.
Normaliter zou dit dan d.m.v. een ToString call omgezet worden naar een string wat standaard een type naam zal opleveren, maar door een @ toe te voegen geven we richting Serilog aan dat we dit object als een gestructureerd object willen opslaan.
Zodra je dit dan bijvoorbeeld in de Console/ File logging voorbij ziet komen krijg je typisch de JSON-representatie van de order te zien.
Wat er nu alleen nog ontbreekt is dat je niet eenvoudig door je logs heen kunt zoeken. Dit is waar een “Structured Log Server” van pas komt.
Scoping
We weten nu dat we hele objecten kunnen loggen, maar stel je zou bijvoorbeeld alle logs willen zien gedurende het uitvoeren van 1 specifieke API call? In een traditionele aanpak zou je dan voor iedere log regel een bepaald kenmerk moeten wegschrijven zodat je dit kunt volgen, maar met een moderne aanpak zoals we hier beschrijven kan dit d.m.v. “log scoping”. Bij het aanmaken van een nieuwe log scope voeg je data toe aan alle log acties die binnen deze scope worden uitgevoerd.
ASP.NET maakt automatisch al een nieuwe scope voor ieder request en voegt hier o.a. een unieke request id aan toe. Zou je van 1 foutmelding willen weten wat er nog meer gedurende dezelfde request is gebeurd dan hoef je alleen maar te filteren op de request id die bij deze specifieke foutmelding aanwezig is en je krijgt alle log regels te zien die gelogd zijn gedurende de afhandeling van deze request.
Los van het feit dat ASP.NET Core zelf scopes aanmaakt, kun je dit ook zelf doen. Als voorbeeld zou je een taak kunnen hebben draaien binnen je applicatie en een nieuwe scope voor iedere taak run kunnen aanmaken.
Een voorbeeld hoe je zelf een scope aanmaakt:
using (_logger.BeginScope("Running task {task}. Task Run Id: {taskRunId}", typeof(TTask), taskRunId))
{
...
}
In bovenstaand voorbeeld zou dit betekenen dat je op basis van een taskRunId alle bijbehorende log regels kan opzoeken.
Gevoelige informatie
Hopelijk ben je tot nu toe enthousiast, maar voordat je overal volledige objecten gaat loggen moet je wel even bewust worden van een risico wat hierbij komt kijken:
Let goed op wat je naar je logs wegschrijft!
Het is al heel wat keren voorgekomen dat een bedrijf in het nieuws komt, omdat er bijvoorbeeld wachtwoorden zijn gelekt via logbestanden. Uiteraard wil je geen wachtwoorden en/of gevoelige informatie wegschrijven!
Eigenlijk is dit risico altijd al wel aanwezig geweest, maar met meer data betekent dat dit risico alleen maar groter wordt
Gelukkig zijn er wel een aantal dingen die je kunt doen om dit te voorkomen. Je kunt simpelweg ervoor zorgen dat deze objecten met gevoelige informatie niet gelogd worden of je gaat deze data maskeren/wegpoetsen voordat ze weggeschreven worden.
Als voorbeeld hoe je dit zou kunnen doen kijken we naar hoe een open source library (https://github.com/destructurama/attributed) dit doet d.m.v. attributes die je boven je properties/ fields kunt plaatsen:
public Guid Id { get; }
[NotLogged]
public string Name { get; }
[LogMasked(ShowFirst = 3)]
public string SocialSecurityNumber { get; }
Zodra dit object vervolgens gelogd wordt dan zal er geen “Name” aanwezig zijn en zal er maar een gedeelte van het “SocialSecurityNumber” zichtbaar zijn.
Voorbeeld:

Log sinks
Wanneer je gebruik maakt van een logging library die gestructureerde logging ondersteund, maar dit dan wegschrijft naar een formaat waar deze data als platte tekst opgeslagen wordt dan maak je nog niet optimaal gebruik van gestructureerde logging. Hiervoor kun je beter gebruik maken van een opslag plek die deze gestructureerde logging wel volledig opslaan en het mogelijk maakt om door de logs heen te zoeken, te filteren en te visualiseren. Ook zijn er services die vervolgens ook alerts kunnen genereren aan de hand van logs.
Er zijn diverse cloud oplossingen, maar ook oplossingen die je zelf kunt hosten. Welke je gebruikt ligt vooral aan eigen voorkeuren, het bedrijfsbeleid en/ of eventuele wetgevingen waar je je aan moet houden.
Enkele voorbeelden zijn:
Seq
Seq is the intelligent search, analysis, and alerting server built specifically for modern structured log data.
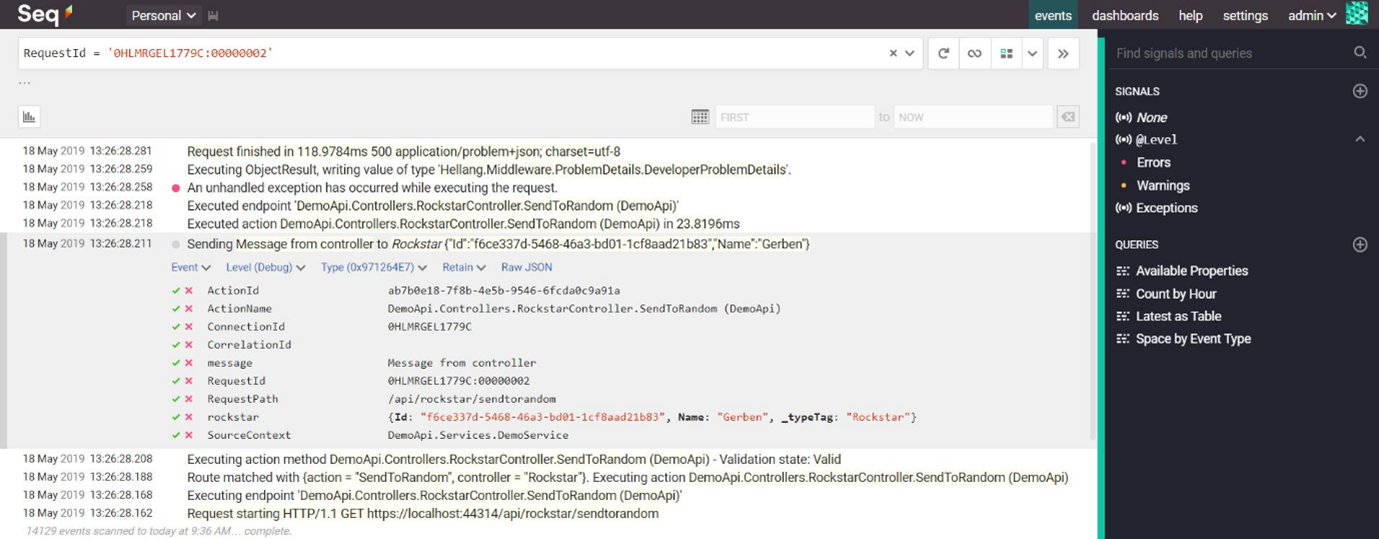
Seq is dus een logging server waar logging naar toe gestuurd kan worden en tegelijkertijd zeer makkelijk doorheen gezocht kan worden. Perfect voor development purposes, maar ook zeker geschikt voor productiedoeleinden.
Seq biedt in ieder geval naast het doorzoeken van logs ook mogelijk om dashboards en alerts aan te maken.
Ingestion gaat op basis van een HTTP endpoint, maar er zijn ook tools die file based logs kunnen pushen naar seq.
Seq moet je overigens wel zelf beheren.
Azure Monitor
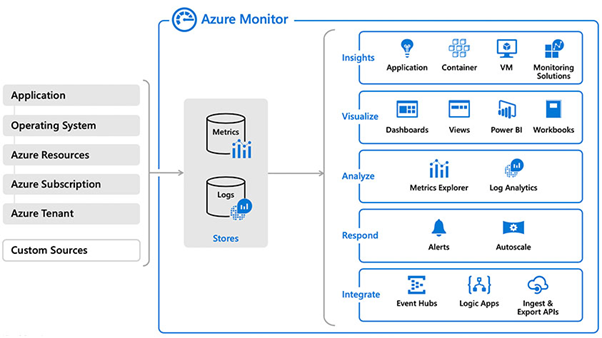
Collect, analyze, and act on telemetry data from your Azure and on-premises environments. Azure Monitor helps you maximize performance and availability of your applications and proactively identify problems in seconds.
Waar je voorheen Application Insights en Azure Log Analytics had zijn deze tegenwoordig ondergebracht bij Azure Monitor. Azure Monitor is een volledige managed omgeving. Bied in ieder geval logging (log analytics), dashboards, alerts, metrics en Application Insights wat allerlei dependencies, metrics, etc inzichtelijk maakt binnen een applicatie.
Elastic Stack
That’s Elasticsearch, Kibana, Beats, and Logstash (also known as the ELK Stack). Reliably and securely take data from any source, in any format, then search, analyze, and visualize it in real time.
De “Elastic Stack” (voorheen ELK stack) is niet zozeer 1 product, maar meerdere in 1:
- Elasticsearch
- Logstash
- Kibana
- Beats
- Logstash
Elasticsearch: Elasticsearch is een gedistribueerd, RESTful search en analytics engine. Hier worden de logs dus in opgeslagen en bied het andere tools de mogelijkheid om hier doorheen te zoeken.
Logstash is het beste te vergelijken met een dataprocessing pipeline. Het pakt verschillende bronnen en stuurt dit door naar iets anders zoals elasticsearch.
Kibana is de UI schil die het mogelijk maakt om met de data in elasticsearch te kunnen werken.
Logstash is een logging collectie pipeline waarbij logs gefiltered en verstuurd kunnen worden naar andere elasticsearch of andere services.
Beats is bedoeld om logs vanuit honderden of duizenden lichtgewicht machines naar logstash of elasticsearch te sturen.
De elastic stack kan zelf gehost worden of als managed product afgenomen worden bij verschillende partijen.
Het is een zeer populair platform met enorm veel mogelijkheden. Denk aan logging, dashboards, alerts en machine learning.
Console
Als developers zullen we al best veel logging gezien hebben in onze console via “stdout”. Wat nu als ik je vertel dat dit ook gewoon in productie wordt gebruikt? Wanneer je je applicatie in bijvoorbeeld een kubernetes cluster draait wel in ieder geval! Wanneer je veel verschillende applicaties moet beheren dan wil je niet per applicatie bezig zijn met zaken zoals waar de logging heen moet. Dat is iets wat je over kunt laten aan bijvoorbeeld de beheerder van je cluster. Een populaire strategie is dan te loggen naar de console, waarna een andere applicatie deze console output uitleest, parsed en pushed naar een service waar de logs opgeslagen kunnen worden.
Twee populaire tools hiervoor zijn FluentD en FluentBit.
Ze “collecteren” logs van verschillende bronnen (file, http, etc), filteren en transformeren dit (indien nodig) en zorgen dat de logs weer doorgestuurd worden naar andere services zoals een Elasticsearch, Azure Monitor, Seq, etc.
Voor wie hier nu Azure Monitor gebruikt op een linux omgeving: Je gebruikt FluentD al zonder dat je dit wellicht al wist.
Om bijvoorbeeld in een basic kubernetes cluster alle logging op te vangen en door te sturen kun je een deamonset definiëren (Een deamonset is iets wat op alle nodes moet draaien) met daarin FluentBit die vervolgens alle console output van alle applicaties in het cluster forward naar bijvoorbeeld Elasticsearch.
Gebruik je AKS (Azure Kubernetes Service) dan is een koppeling met Azure Monitor zeer eenvoudig al out-of-the-box mogelijk zonder dat je hier zelf iets voor hoeft te doen.
Conclusie
Hopelijk is het nu een beetje duidelijk wat gestructureerd loggen nou precies is en hoe je hier je voordeel uit kunt halen. Ook heb ik enkele services/tools genoemd die je hiervoor kunt gebruiken.
Gebruik je nu nog helemaal geen structured logging, maar zou je dit wel willen? Begin dan bij development… Zorg dat je bijvoorbeeld Seq lokaal draait in een docker container. De toegevoegde waarde van structured logging zal snel gezien gaan worden!
Vond je dit verhaal interessant en had je nog wat vragen? Neem gerust contact met me op via LinkedIn.
 Vincent Hendriks
Vincent Hendriks
Vincent Hendriks is een Software Engineer met meer dan 15 jaar ervaring en een enorme passie voor het vak. Vincent heeft een zeer brede ervaring in onderwerpen zoals C#, .NET/.NET Core, Software achitectuur, CQRS, Event Sourcing, SQL, Azure, Docker en nog veel meer.