 SDN – Software Development Network SDN – Software Development Network – De SDN verenigt software ontwikkelaars, architecten, ICT managers, studenten, new media developers en haar businesspartners met algemene interesse in alle aspecten van Microsoft en .NET.
SDN – Software Development Network SDN – Software Development Network – De SDN verenigt software ontwikkelaars, architecten, ICT managers, studenten, new media developers en haar businesspartners met algemene interesse in alle aspecten van Microsoft en .NET.
SDN MAGAZINE 149
Jan de Vries
Het zal je niet zijn ontgaan dat Open AI en hun bekende Large Language Model implementaties (zoals ChatGPT) veel aandacht hebben gekregen. Vele lezers zullen hier dan ook gebruik van hebben gemaakt, wellicht ook voor het maken van code. Een andere bekende LLM-implementatie is natuurlijk GitHub Copilot, welke als doel heeft om “natural language” vragen naar software implementaties (code) te vertalen.
Dit is allemaal indrukwekkend als gebruiker, maar het voegt nog niet direct waarde toe voor de oplossingen die we voor onze bedrijven maken. Als ontwikkelaar kunnen we de verschillende endpoints (completion, chat, embedding) aanroepen van de Open AI instanties, maar om daar nuttige output uit te krijgen dient er goede input (prompt) te worden gemaakt. Dit integreren in een bestaande oplossing kan voor uitdagingen zorgen, plus dat het maken van dergelijke input wel een vak apart blijkt te zijn.
Voor een goede implementatie van een LLM in jouw applicatie is het noodzakelijk om anders te gaan denken over softwareontwikkeling en dit op een specifieke manier op te zetten.
Wat gaat Semantic Kernel voor mij doen?
Het is relatief eenvoudig om te werken met Azure Open AI, deze heeft namelijk verschillende endpoints beschikbaar om acties uit te voeren. Een voorbeeld, uit de MS Learn documentatie, hoe het completion endpoint van GPT-3.5 Turbo aangeroepen kan worden met de C# SDK.
using Azure;
using Azure.AI.OpenAI;
using static System.Environment;
string endpoint = GetEnvironmentVariable(“AZURE_OPENAI_ENDPOINT”);
string key = GetEnvironmentVariable(“AZURE_OPENAI_KEY”);
// Enter the deployment name you chose when you deployed the model.
string engine = “gpt-35-turbo-instruct”;
OpenAIClient client = new(new Uri(endpoint), new AzureKeyCredential(key));
string prompt = “When was Microsoft founded?”;
Console.Write($”Input: {prompt}\n”);
Response<Completions> completionsResponse =
await client.GetCompletionsAsync(engine, prompt);
string completion = completionsResponse.Value.Choices[0].Text;
Console.WriteLine($”Chatbot: {completion}”);
Uiteraard is bovenstaande voorbeeld code, maar geeft al goed weer hoe Azure Open AI geïntegreerd kan worden in bestaande software.
Helaas wordt de chat-ervaring heel veel gebruikt om de kracht van een LLM te laten zien. In veel software-oplossingen is dit niet een ervaring die wordt aangeboden of nuttig wordt geacht.
Ook zullen de meeste oplossingen meer doen dan alleen informatie vergaren uit een LLM. Normaliter zal dat in een of meerdere databronnen zijn opgeslagen, zijn er algoritmes ontwikkeld om waarde toe te voegen aan de data, etc.
Het samenvoegen van de mogelijkheden die een LLM biedt en een bestaande softwareoplossing is iets waar frameworks zoals Semantic Kernel in uitblinken. Een ander bekend framework, dat een vergelijkbaar doel heeft is LangChain. Een quote van de LangChain site:
LangChain is a framework for developing applications powered by language models. We believe that the most powerful and differentiated applications will not only call out to a language model via an api, but will also:
- Be data-aware: connect a language model to other sources of data
- Be agentic: Allow a language model to interact with its environment
As such, the LangChain framework is designed with the objective in mind to enable those types of applications.
Deze quote geeft goed weer waaraan gedacht moet worden bij het implementeren van een LLM binnen jouw applicatie en waarom een framework zoals LangChain of Semantic Kernel gebruikt dient te worden.
Beide frameworks zijn prima oplossingen, maar als lezer van dit magazine is het waarschijnlijk een goed idee om voor Semantic Kernel te kiezen. De reden? Semantic Kernel heeft ondersteuning voor C#, waar LangChain dat op dit moment niet heeft.
Door het gebruik van Semantic Kernel kunnen flows van applicatie logica worden opgebouwd (plans) en automatisch worden uitgevoerd. Deze plans worden door een LLM opgesteld op basis van documentatie van de applicatie logica.
Uiteraard kunnen ook reguliere prompts worden gebruikt voor het maken van complexe output.
Een voorbeeld hoe Semantic Kernel te werk gaat.
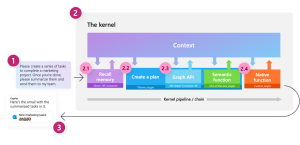
Stap 1 is de input leveren, in dit geval een vraag om iets uit te voeren. In stap 2 worden verschillende onderdelen uitgesplitst, zoals het opvragen van de conversatie (2.1), een plan maken (2.2) op basis van beschikbare connectoren en semantic functions (2.3) en native functions (2.4). Zodra het plan is gemaakt en uitgevoerd kan de output worden geretourneerd naar de gebruiker (3).
Klinkt goed, hoe ga ik het dan gebruiken?
Eigenlijk kan iedereen direct starten met Semantic Kernel te gebruiken, het enige dat noodzakelijk is, is het toevoegen van een Azure Open AI instantie met een model. Er kan ook met de publieke Open AI instantie worden gewerkt, mocht je dat graag willen.
Zodra deze instantie bestaat kunnen de gegevens worden gebruikt voor het instantiëren van een `IKernel` object, wat als basis dient voor het werken met Semantic Kernel. Ten tijde van schrijven is net de v1.0.0 Beta1 SDK uitgebracht. Het framework staat nog in de kinderschoenen, maar het lijkt er naar op dat er snel een stabiele versie beschikbaar komt.
Het maken van een `IKernel` object is een relatief zware operatie, waardoor er over moet worden nagedacht welke lifetime dit object moet gaan krijgen binnen je applicatie. Een voorbeeld uit een van m’n eigen samples.
s.AddSingleton(
typeof(IKernel),
s =>
{
var kernel = new KernelBuilder()
.WithAzureTextCompletionService(
openAiSettings.ServiceModelName,
openAiSettings.ServiceCompletionEndpoint,
openAiSettings.ServiceKey
)
.WithAzureTextEmbeddingGenerationService(
openAiSettings.EmbeddingsDeploymentId,
openAiSettings.ServiceCompletionEndpoint,
openAiSettings.ServiceKey
)
.Build();
Na registratie kan het object worden gebruikt om een plan te maken.
Er zijn verschillende planners beschikbaar in Semantic Kernel, BasicPlanner, ActionPlanner, SequentialPlanner en StepwisePlanner. Alle vier hebben een ander doel. Wanneer je net start is het leuk om te beginnen met een `ActionPlanner`, deze maakt een plan met een enkele stap. De echte waarde zit hem echter in de `SequentialPlanner` en `StepwisePlanner`. De `SequentialPlanner` is namelijk in staat om van een vraag (commando) een plan te maken van een of meerdere stappen die moeten worden uitgevoerd op basis van de informatie en beschikbare connectoren en plugins die beschikbaar zijn.
De `StepwisePlanner` is een evolutie van de `SequentialPlanner`. In essentie zijn ze vergelijkbaar, maar de `StepwisePlanner` heeft als voordeel dat het ook kan leren. Wanneer het een plan heeft opgesteld om stap 1, 2, 3 uit te voeren en tijdens het uitvoeren er achter komt dat stap 2 niet de gewenste output geeft, dan wordt er een nieuwe plan opgesteld en kan er een alternatief plan worden opgesteld om stap 1, 4, 5, 3 uit te voeren om het commando succesvol te beantwoorden. De planner kan dit oneindig doen, dus het is aan te raden om een limiet op het aantal retries te zetten.
Bij deze een voorbeeld hoe de `SequentialPlanner` gebruikt kan worden.
Microsoft.SemanticKernel.Planning.Stepwise.StepwisePlannerConfig config = new()
{
MaxTokens = 2000,
MaxIterations = 2,
};
var planner = new StepwisePlanner(kernel, config);
var plan = planner.CreatePlan(request);
Microsoft.SemanticKernel.AI.TextCompletion.CompleteRequestSettings settings = new()
{
MaxTokens = 2000,
};
return await plan.InvokeAsync(kernel.CreateNewContext(), settings: settings);
Hoe voeg ik stappen toe aan het gemaakte plan?
Het antwoord op deze vraag is: Niet!
Het is niet de bedoeling om zelf aan het plan te gaan sleutelen en daarna uit te gaan voeren. Mocht je zelf stappen toegevoegd willen zien, om zo bijvoorbeeld business logica toe te voegen, bedrijfsprocessen te activeren, of iets totaal anders, dan moeten er Functions worden gemaakt.
Hoe maak ik mijn eigen Plugins of Functions?
Er zijn momenteel twee type Functions, namelijk Semantic Functions en Native Functions. Alle type Functions worden gebundeld in Plugins. Eerder werden deze Plugins nog Skills genoemd. Het komt dus nog voor dat in de documentatie en API van Semantic Kernel nog her en der de term Skills voorbijkomt, dit zal in de loop der tijd veranderen.
Semantic Functions
Een Semantic Function is niets anders als een prompt. Bij deze een voorbeeld voor het samenvatten van een HTML-pagina.
The content is in the below block.
###
{{$input}}
###
Ignore all of the HTML markup and focus on the actual content.
Summarize the actual content.
Bij een dergelijke prompt, welke wordt bewaard in een `skprompt.txt` bestand, dient een `config.json` bestand met de configuratie voor de Semantic Function te worden toegevoegd. Deze configuratie bevat omschrijvingen van de input parameters, het doel van de Function en enkele andere parameters om bijvoorbeeld de temperatuur van het antwoord te tunen. Een voorbeeld van de `config.json` voor bovenstaande prompt.
{
“schema”: 1,
“type”: “completion”,
“description”: “Create a summary from the specified HTML content.”,
“completion”: {
“max_tokens”: 2048,
“temperature”: 0.3,
“top_p”: 0.0,
“presence_penalty”: 0.0,
“frequency_penalty”: 0.0
},
“input”: {
“parameters”: [
{
“name”: “input”,
“description”: “The HTML content that needs to be summarized.”,
“defaultValue”: “”
}
]
}
}
Door een correcte omschrijving toe te voegen is Semantic Kernel (en onderwater het LLM) in staat om een plan op te stellen met de beste Functions welke gebruikt kunnen worden om een antwoord op een vraag te verkrijgen.
Native Functions
Native Functions zullen de meeste lezers aanspreken. Het stelt je namelijk in staat om de bestaande codebase te ontsluiten in een Plan. Om bestaande code te ontsluiten dienen er enkele attributen te worden toegevoegd op de entry-points van de logica. Op moment van schrijven zijn dit de attributen `SKFunction` en een `Description`. De eerste geeft aan dat het hier gaan om een Native Function welke door Semantic Kernel gebruikt kan worden. De tweede wordt door Semantic Kernel gebruikt om te bepalen of een Function gebruikt moet worden om een vraag/commando te beantwoorden. Om in het domein van de vorige voorbeelden te blijven, hier een voorbeeld Native Function voor het downloaden van de HTML van een website.
[SKFunction, Description(“Retrieve the body from a specified website URL.”)]public async Task<string> GetBody(string websiteUrl)
{
logger.LogDebug(“Retrieving the content for `{websiteUrl}`.”, websiteUrl);
var content = await GetContent(websiteUrl);
return content;
}
Wanneer alle, of veel, logica binnen jouw applicatie wordt ontsloten als een Native Function, dan kunnen complexe flows eenvoudig worden opgesteld en uitgevoerd. Dit is iets dat wij binnen ons project veel gebruiken.
De Functions toevoegen
Semantic Kernel komt standaard met ingebouwde Plugins en bijbehorende Functions. Het toevoegen van jouw eigen Plugins is ook mogelijk door deze aan het `IKernel` object toe te voegen.
Zie hier een voorbeeld van bovenstaande Functions.
void AddSemanticSkills()
{
logger.LogInformation(“Importing semantic skills”);
string skillsPath = Path.Combine(Path.GetDirectoryName(Assembly.GetExecutingAssembly().Location)!, “GenerativeAi”, “SemanticSkills”);
kernel.ImportSemanticSkillFromDirectory(skillsPath, “Domain”);
}
void AddNativeSkills()
{
logger.LogInformation(“Importing native skills”);
kernel.ImportSkill(new DownloadContent(s.GetRequiredService<IHttpClientFactory>(), s.GetRequiredService<ILogger<DownloadContent>>()), “MySkills”);
}
Conclusie, moet ik altijd Semantic Kernel gebruiken?
Het korte antwoord hierop is: Nee!
Het gebruik maken van Semantic Kernel en een LLM biedt veel voordelen voor het maken van complexe flows van logica. Wij maken hier heel veel gebruik van, omdat we van tevoren niet alle flows binnen de applicatie kunnen definiëren. En al zouden we alle flows kunnen definiëren, dan zou dat resulteren in een enorm complexe decision tree. In ons geval biedt Semantic Kernel en de onderliggende LLM dus heel veel voordelen.
Zo zal er per situatie beoordeeld moeten worden of het echt voordelen biedt om een vraagstuk van de business (gebruikers) te beantwoorden.
Wel adviseer ik om deze frameworks goed in de gaten te houden, want mocht het momenteel nog geen direct nut hebben om te gebruiken binnen jouw applicatie, dan is dit nut er over een tijdje misschien wel. En zoals eerder geschreven, stelt dit je in staat om complexe vraagstukken op een andere manier te implementeren welke mogelijk tot een eenvoudigere codebase resulteert.
De voorbeelden uit dit artikel zijn geplukt uit de volgende GitHub repository: https://github.com/Jandev/sk-plugin-sample
Deze repository bevat enkele voorbeelden voor het maken van plugins en het toevoegen van een publieke Open AI plugin binnen je eigen applicatie om zo extra functionaliteit toe te voegen aan een applicatie.

Bio
Jan werkt als een software engineer aan Microsoft Azure. Op dit moment werkt hij in het team van Microsoft Cloud for Manufacturing aan een grote schaalbare oplossing binnen dat domein.
In de jaren hiervoor heeft hij als consultant vele rollen gehad met focus op het ontwerpen en ontwikkelen van oplossingen voor klanten binnen Microsoft Azure.
Mocht je meer van hem willen lezen, dan is het aan te raden om hem te volgen op zijn blog (https://jan-v.nl) of een van de social media kanalen.