 SDN – Software Development Network SDN – Software Development Network – De SDN verenigt software ontwikkelaars, architecten, ICT managers, studenten, new media developers en haar businesspartners met algemene interesse in alle aspecten van Microsoft en .NET.
SDN – Software Development Network SDN – Software Development Network – De SDN verenigt software ontwikkelaars, architecten, ICT managers, studenten, new media developers en haar businesspartners met algemene interesse in alle aspecten van Microsoft en .NET.
Auteur: David de Hoop
SDN MAGAZINE 145 2022
DevOps Consultant, Platform Engineer, SRE? Je ziet tegenwoordig door de bomen het bos niet meer. De ene na de andere vacature komt voorbij in je LinkedIn inbox met deze nietszeggende functietitels. Uit de omschrijving haal je waarschijnlijk dat ze allemaal iets met DevOps te maken hebben, máár wat is nu echt het verschil?
Functietransformatie
DevOps wint nog altijd aan terrein. Veel organisaties plannen of zitten inmiddels middenin een DevOps transformatie. Dit is niet gek, immers werken volgens de DevOps filosofie is ongekend populair en zorgt voor enorm veel voldoening en werkplezier bij developers, mits goed geïmplementeerd. In organisaties met een grote IT-afdeling en veel componenten die gedeeld worden met meerdere teams kunnen vaak niet alle verantwoordelijkheden verschoven worden naar het development team. In deze DevOps transformaties is vaak behoefte aan mensen die de verschillende IT platformen bouwen en beheren, en die de operatie van de vaak complexe integraties tussen meerdere systemen bewaken. Kortom er is behoefte aan een meer hybride rol binnen de IT operatie wiens focus niet primair bij één team of applicatie ligt. Hier ligt de geboorte van de Platform en Site Reliability Engineer (SRE) aan ten grondslag.
Site Reliability Engineering
De term Site Reliability Engineering (SRE) komt van oorsprong bij Google vandaan en werd al in 2003 geïntroduceerd. Net als DevOps is SRE niet bedacht als rol of functie maar is het een combinatie van principes en best practises uit Software Engineering en past deze toe binnen het IT operations domein. De populariteit van SRE als aparte functie is sterk toegenomen sinds 2016 wanneer steeds meer multinationals een DevOps transformatie ondergingen. Zij hebben behoefte aan aparte teams binnen de IT afdelingen die taken onafhankelijk van de development teams kunnen oppakken, werkzaamheden die vooral met de dagelijkse operatie van de software en de systemen te maken hebben.
Het verschil tussen een DevOps en Site Reliability Engineer zit hem dan ook met name in de plek binnen de DevOps lifecycle waar hun werkzaamheden zich bevinden. Waar een DevOps engineer zich vooral bezig houdt met het opzetten van CI/CD en het in productie krijgen van de software en dus vooral in de Package en Release fase actief is, begint het werk van de Site Reliability Engineer eigenlijk pas wanneer de software in productie draait. Deze houdt zich vooral bezig met Observability en monitoring van de applicatie, capaciteits- en kostenmanagement van de infrastructuur en ook met SLA’s en het incident management proces. Een DevOps transformatie binnen een grote organisatie raakt namelijk ook de traditionele ITIL processen. Deze worden na de transformatie ook ingevuld door de SRE. Daarnaast houden SREs zich ook bezig met het verbeteren van de betrouwbaarheid van de applicaties die zijn monitoren, bijvoorbeeld door het toepassen van Chaos Engineering.
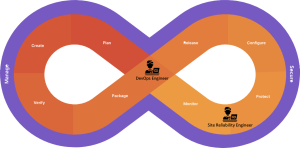
De positie van de DevOps en Site Reliability
Engineer binnen de DevOps lifecycle.
Het “Platform” als interne service provider
Naast het inzetten van SRE is er bij grotere bedrijven vaak nóg een probleem bij een DevOps transformatie. Je wilt niet dat elk development team een eigen tenant in de public cloud gaat hosten of dat elk development team het wiel opnieuw uitvind. Daarnaast zijn er sectoren die streng gereguleerd worden waarbij centraal geregelde governance gewoon een vereiste is.
Om dit probleem toch op een agile manier te kunnen oplossen zijn veel van deze bedrijven begonnen met één of meerdere projecten waarbij een aantal development teams werken aan een intern platform. Dit kan puur cloud infrastructuur zijn, bijvoorbeeld in de vorm van een Cloud Center of Excellence (CCoE), maar ook een integratieplatform, centrale API gateway of datawarehouse. Deze projecten functioneren eigenlijk volledig als een aparte leverancier voor de organisatie, alleen dan binnen diezelfde organisatie. De development teams zijn dan klant en tevens afnemer van dit platform. Op deze manier is het ook binnen deze teams mogelijk om agile te werken op een vraag gestuurde manier én kun je toch een mate van gecentraliseerde controle houden op de operatie van de IT infrastructuur en kun je zaken als governance, kostenbeheersing en heel belangrijk, security centraal regelen.
De engineers die aan zo’n platform werken worden dan steevast Platform Engineers genoemd. Een nogal nietszeggende functietitel in een vacature als je niet weet om wat voor platform het gaat. Vaak zijn dit functies waarbij zowel de competenties van een cloud- of netwerk engineer gevraagd wordt samen met enkele competenties van een meer traditionele DevOps rol. Want ook op het interne platform wil je zoveel mogelijk automatiseren. Misschien wil je voor deze platforms zelfs ook wel aparte SREs hebben die zich ontfermen over de monitoring en observability ervan. Een van de kenmerken van deze interne service providers is dan ook dat je ze in de DevOps transformatie net zo behandeld als elke andere applicatie. Alleen gaat het in dit geval dan niet om een webapplicatie of mobiele app, maar om een infrastructuur platform, datawarehouse of API gateway. Trouwens een dergelijk platform heeft vaak ook API’s op de back-end of een webapplicatie als front-end. Dus eigenlijk is het ook helemaal niet zo raar om deze net zo te behandelen als de applicaties die uiteindelijk van dit platform gebruik gaan maken.
 Bio:
Bio:
David de Hoop is Special Agent (thought leader) bij Team Rockstars IT. Als solution architect adviseert hij organisaties op het gebied van Public Cloud, DevOps transformaties en Microsoft Azure. David is een fervent Agile aanhanger en DevOps evangelist. Daarnaast haalt hij veel energie uit het geven van workshops en spreken op conferenties over de hele wereld zoals laatst in Hamburg op de ContainerDays en in India op de Azure Community Conference.
Twitter: https://twitter.com/davidshadoow
LinkedIn: https://www.linkedin.com/in/daviddehoop/
Website: https://www.teamrockstars.nl/developers/special-agent-david-de-hoop/
Dé DevOps Engineer bestaat niet
Kortom zoals je hebt kunnen lezen bestaat dé DevOps Engineer niet. Zowel Platform als Site Reliability Engineering zijn onderdeel van de DevOps lifecycle en vervullen zeker in de wat grotere organisaties een belangrijke rol. Waar de competenties voor deze functies ook gelijkenissen vertonen zijn de dagelijkse werkzaamheden behoorlijk verschillend, zoals ook in de volgende vergelijking te zien is.
DevOps EngineerSite Reliability EngineerPlatform Engineer
| DevOps Engineer | Site Reliability Engineer | Platform Engineer | |
| Verantwoordelijkheden | Is verantwoordelijk voor het in productie krijgen van nieuwe applicaties. | Is verantwoordelijk voor het draaiend houden en monitoren van bestaande applicaties. | Is verantwoordelijk voor de ontwikkeling van de onderliggende infra- en/of datastructuur. |
| Key Focus | Focust zich op automatisering van het build en release proces. | Focust zich op de observability, monitoring en stabiliteit van draaiende applicaties. | Focust zich op de capaciteit, beveiliging en governance van de infrastructuur en/of datastore. |
| Plaats in de organisatie | Onderdeel van een development team | Onderdeel van een development team óf operationele afdeling | Onderdeel van een interne service provider. |
Tabel 1. Vergelijking tussen DevOps, SRE en Platform Engineers.
In de kern houden ze zich allemaal bezig met een bepaalde mate van automatisering, maar waar de DevOps engineer zich vaak toch dichter bij het development team begeeft, zitten de SRE en Platform Engineer meer ingebed in de IT operatie. In die zin zou je kunnen zeggen dat de SRE en Platform Engineer de moderne evolutie van de traditionele systeem- en applicatiebeheerders zijn.
Deze analogie laat zien dat de rol van zowel de SRE als Platform engineer binnen grote organisaties belangrijk zijn voor een succesvolle DevOps transformatie. Door de hedendaagse complexiteit van microservices architecturen en public cloud platformen is er behoefte aan meer diepgaande technische kennis binnen het operationele IT domein. Het ontwikkelen van goede monitoring met betrouwbare en betekenisvolle informatie en het snel kunnen opvolgen van security incidenten is van levensbelang voor een soepele operatie van de gehele bedrijfsvoering die steeds meer door IT gedreven wordt.
Daarnaast is wendbaarheid van de IT operatie in de snel veranderende wereld van public cloud een vereiste. Hier is in het heden en op de korte termijn dan ook een belangrijke rol weggelegd voor de SRE en de Platform Engineer.